DaSiC 7 (2023) Linguistics and Data Science in Collaboration 発表資料
Shin Aasakawa, all rights reserved.
https://opensource.org/license/mit/
機械学習からみた言語モデルの鏡
LLMs that reflect your needs as well as your intelligence could be a Mirror of Erised (“Desired” spelt backward), which in the world of Harry Potter “shows us nothing more or less than the deepest, most desperate desire of our hearts. [Sejnowski2022](https://doi.org/10.1162/neco_a_01563)
Table of contents: part 1 第一部目次 (14:10-14:50)
- 計算論的モデルへの招待 Invitation to computational modelings (10 min.)
- p 値廃止 Ban of p-values
- データサイエンスの 2 つの文化 Two cultures in data science
- 神経科学に対する機械学習の 4 つの役割 Four roles of machine learning to neuroscience
- 記号表象と分散表象との橋渡し (あるいは,規則に基づく操作と幾何学的操作) Building a bridge between symbolic and distributional representations (or between rule-based and vector-based geometrical operations) (10 min.)
- ワンホット符号化と埋め込みベクトル one-hot encodings and embedding vectors
- ソフトマックス関数と結合係数行列 Softmax function and (tying) weight matrices
- 符号化器・復号化器モデル Encoder-decoder models (10 min.)
- 言語モデル Language models
- 翻訳モデル Translation models
- 注意機構 Attention mechanism
- Transformer
- 微調整と転移学習 Fine tuning and transfer learning (10 min.)
- 最終直下層に含まれている情報 Information containing in penultimate layers
- 大規模言語モデルから特定の課題へ,言い誤りの型からパラメータ推定 What models do from LLM to specific tasks is analogous to what speech errors be modified to those who produced them.
- マルチモーダル,マルチタスク統合へ向けて Towards Multi-modal and multi-task integrations
Table of contents: part 2 第二部目次 (15:15-16:15)
- Dell+ モデルによるいい誤りのシミュレーション Dell+’s model for speech errors
- ソフトマックス関数の温度パラメータ thermal parameter in softmax function
- 患者ごとの微調整
- A encoder-decoder model for word repetition tasks
Table of contents: part 3 第三部目次 (16:25-17:40)
- A model of 百人一首 implemented on Transformer
- Horizontal and vertical errors in speech errors
主張 Takeaways
- 大規模言語モデル (LLM),一般画像錦 (ImageNet) で事前訓練されたモデルに対して,転移学習 transfer learning を行うことで,関心領域の課題を解くモデルを作成
- 関心課題に特化したモデルに対して,任意の条件とデータとを用いて,微調整 fine-tuning を行うことで,条件間の差異や生成機序を解明。
- モデル,データ,パラメータ の三項は,言語学的規範,行動・臨床データ,機械学習モデルの三項と連結。微調整に用いる条件は,制約条件付き最適化 constrained optimization とみなしうる。このことは,データサイエンスにおける,モデルとパラメータの関する双対性原理 duality principle として定式化可能
キーワード keywords
符号化・復号化モデル,転移学習,微調整,トランスフォーマー,注意,ソフトマックス,ワンホットベクトル, 埋め込み表現,ラグランジェ双対性
Encoder-decoder models, Transfer learning, Fine-tuning, Transformer, Attention, Softmax, onehot vector, Embeddings, Lagrange duality,
0. 背景
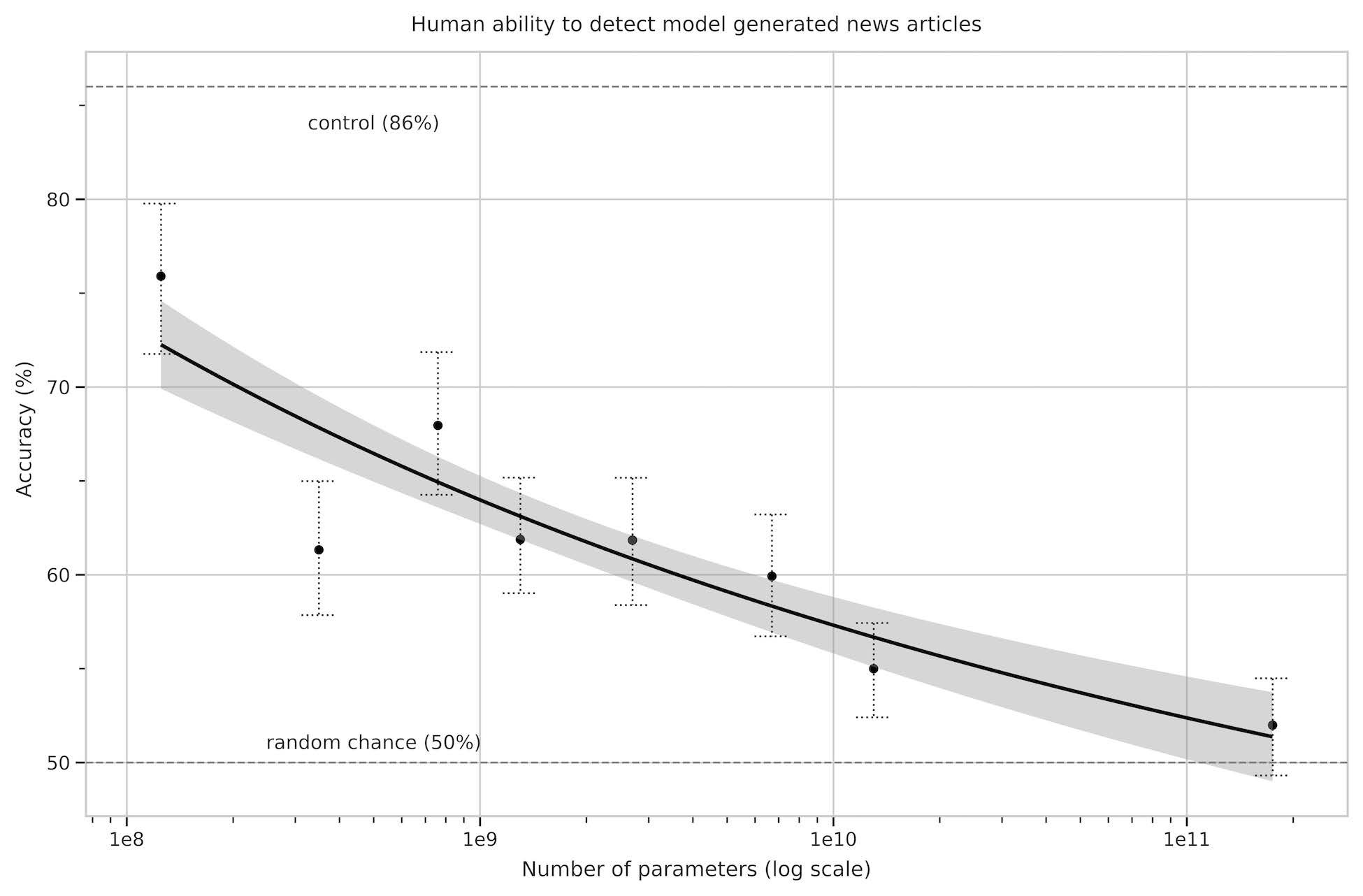
0.1 生成 AI の性能向上
0.2 Modeling
- 記述モデル description model 箱と矢印モデルなど,質的予測
- データ適合モデル data-fitting model LDA と SVM との違いにあらわれている
- アルゴリズムモデル algorithm model
0.3 機械学習の定義,古典的定義と現代的定義
- アーサー・サミュエル Arthur Samuel (1959): 機械学習とは,明示的にプログラムで指示せずにコンピュータに学習させる能力を研究する分野である。
- “field of study that gives computers the ability to learn without being explicitly programmed”
- トム・ミッチェル Tom Mitchell (1999): ある課題 T とその成績 P の評価からなる経験 E をとおして学習するコンピュータプログラムを機械学習という。
- “A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E.”


右: Tom Mitchell from <http://wamc.org/post/dr-tom-mitchell-carnegie-mellon-university-language-learning-computer>
0.3 機械学習と心理統計学の違い
仮説検定とパラメータチューニングの差異は,母集団の相違に期すのか,それとも選択しているモデルによるものなのか。 心理統計では,データを説明する努力よりも,母集団の相違,すなわち,帰無仮説が棄却できるか採択されるかに興味がある。 ところが,帰無仮説が正しいかどうかは,選択する統計モデルに依存する。 このとき統計モデルの精度が正しいのかどうかを問題にすることは少ない。 だが,用いるモデルに依存して推論結果が変化するかも知れない。 そうするとモデルの優劣が問題になるであろう。
一方,機械学習では,心理統計の母集団に相当する概念が,汎化性能である。 所与のデータにだけ当てはまるモデルではなく,未知のデータにたいして性能の高いモデルが選択される。 未知のデータ,未学習のデータに対する性能と母集団の差異を,一概に比較することは難しいが,予測精度を高くすることが,現実には用いられる実用性が高い。 応用が可能で,実学として世の中の役に立つ成果を生み出すことができる。
1. 計算論モデルへの招待 Invitation of computational modelings
1.1 P 値廃止 ban of p-values
ASA アメリカ統計学会の声明
- P 値は,データが指定された統計モデルとどの程度相性が悪いかを示すことができる
- P 値は,研究された仮説が真である確率を測定するものではない。そうではなく,データがランダムな偶然だけから,生成された確率を測定するものである
- 科学的な結論やビジネスや政策の決定は,p 値が特定の閾値を超えたかどうかだけに基づくべきではない
- 適切な推論を行うには,完全な報告と透明性が必要である
- P 値や統計的有意性は,効果の大きさや結果の重要性を測定するものではない
-
それ自体では,p 値はモデルや仮説に関する証拠の良い尺度を提供しない。
1.2 Breiman2001 によるデータサイエンスにおける 2 つの文化
- データモデル文化とアリゴリズムモデル文化
- データモデル文化とアルゴリズムモデル文化とは,心理統計で用いられるような統計学モデルを使用する文化を指す。
- 一方,アルゴリズムモデル文化とは,機械学習における統計学的技法を重視する文化である。



From Leo Breiman, Statistical Modeling: The Two Cultures, Statistical Science, 2001, Vol. 16, No. 3, 199–231, doi:10.1214/ss/1009213725. pdf
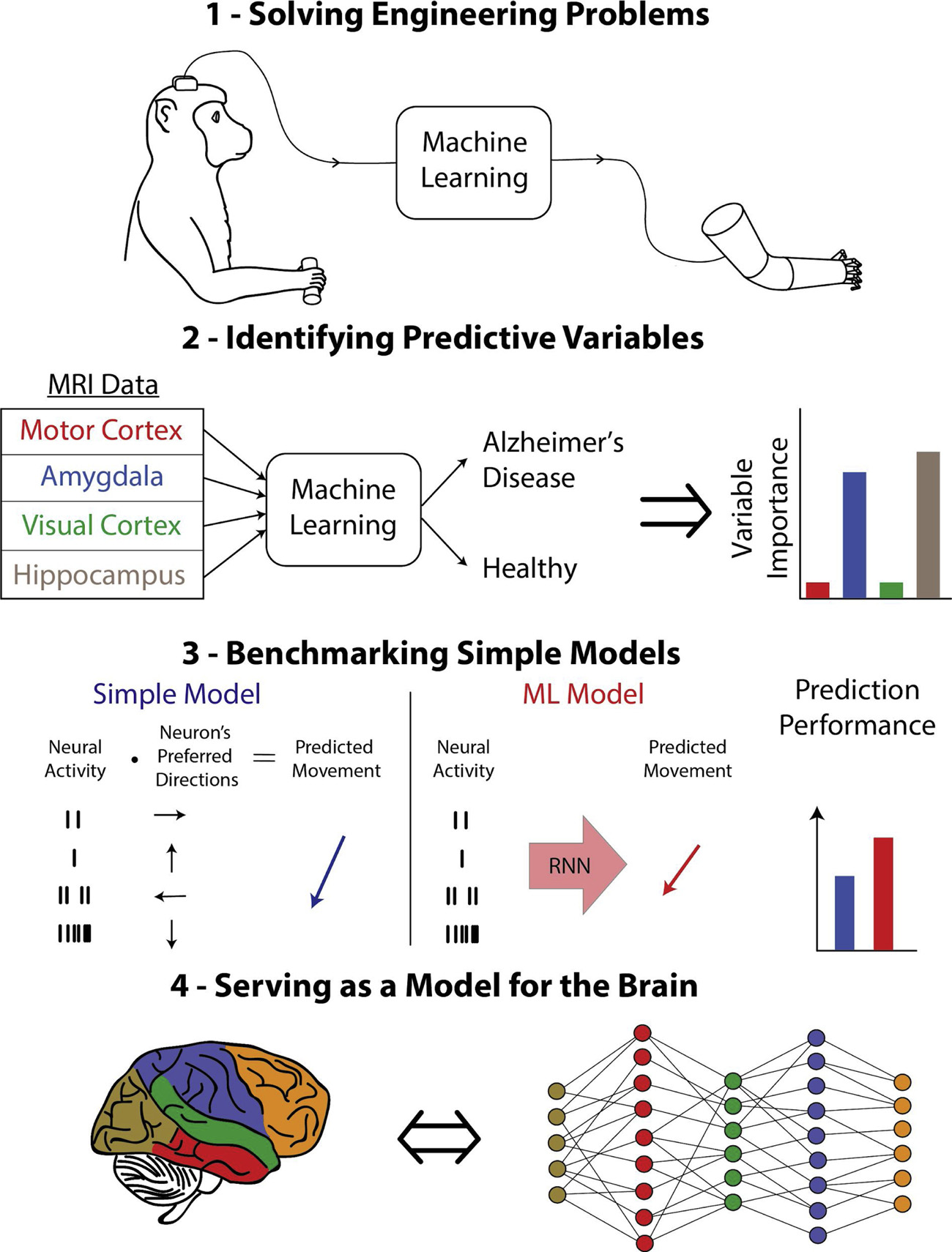
1.3 Glaser+2019 神経科学における機械学習モデルの 4 つの役割
- 工学的な問題の解決 機械学習は, 医療診断, ブレインコンピュータインターフェース, 研究ツールなど, 神経科学者が使用する手法の予測性能を向上させることができる。
- 予測可能な変数の特定 機械学習により, 脳や外界に関連する変数がお互いを予測しているかどうかをより正確に判断することができる。
- 単純なモデルのベンチマーク。 解釈可能な簡易モデルと精度の高い ML モデルの性能を比較することで, 簡易モデルの良し悪しを判断するのに役立つ。
- 脳のモデルとしての役割。 脳が機械学習システム, 例えばディープニューラルネットワークと同様の方法で問題を解決しているかどうかを論じることができる。
2. 記号表現と分散表象との間隙を埋める
- ワンホットベクトル を 分散表現へ
- 分散表現をワンホット表現へ
記号とベクトルとを相互に変換できれば,便利。
- [‘戦’,’争’] の書記表現 [ 1, 1565, 1604, 2]
- [’s’, ‘e’, ‘N’, ‘s’, ‘o’, ‘u’] の音韻表現 [ 1, 37, 7, 14, 37, 8, 6, 2]
同様に,単語 (もしくはトークン) についてすべて付番し,そのトークン番号で表現 (tokenizer)
>>> from transformers import EncoderDecoderModel, BertTokenizer, BertConfig
>>> tknz = BertTokenizer.from_pretrained('sonoisa/sentence-bert-base-ja-mean-tokens-v2')
>>> print(tknz('誰が一番に着くか私には分かりません。').input_ids)
[2, 3654, 14, 52, 246, 7, 816, 609, 28470, 1325, 7, 28450, 155, 20431, 28491, 4263, 8, 3]
>>> print(tknz.convert_ids_to_tokens([2, 3654, 14, 52, 246, 7, 816, 609, 28470, 1325, 7, 28450, 155, 20431, 28491, 4263, 8, 3]))
['[CLS]', '誰', 'が', '一', '番', 'に', '着', 'く', '##か', '私', 'に', '##は', '分', 'かり', '##ま', '##せん', '。', '[SEP]']
>>> tknz('言語学').input_ids
[2, 1882, 112, 3]
>>> tknz.convert_ids_to_tokens([2, 1882, 112, 3])
['[CLS]', '言語', '学', '[SEP]']
>>> tknz('データサイエンス').input_ids
[2, 1676, 14916, 3]
>>> tknz.convert_ids_to_tokens([1676,14916])
['データ', 'サイエンス']
>>> tknz('DaSiC7').input_ids
[2, 28367, 28583, 28535, 28598, 127, 3]
>>> tknz.convert_ids_to_tokens([28367, 28583, 28535, 28598, 127])
['Da', '##S', '##i', '##C', '7']
単語 データサイエンス は データ が 1676 番という ID 番号を持ち,かつ,サイエンスが 14916 番であることが分かる。
したがって,データサイエンスを表現するには,32000 次元のワンホットベクトルを 2 つ用いて,
[0,0,..,1,,...,0,0,0]
のようなベクトルを作成する。このとき,ベクトルの 1 つの要素だけが 1 で,残りすべての要素が 0 であるベクトルをワンホットベクトルと呼ぶ。

- ワンホットベクトルから,埋め込み表現ベクトルを作成するには,変換行列を掛ければ良い
- 埋め込み表現から,ワンホットベクトルに戻すことによって,出力トークンを得る。このためにはソフトマックス関数を用いる
- 指数関数 $e^{x}$ は,$x$ が実数の範囲であれば,正負に関わらず,正の値に変換し,かつ変換後も大小関係が保たれる。すなわち $x > y:\rightarrow\exp(x)>\exp(y)$
- すべて要素が正であれば,各要素の総和を分母とし,分子に,その値をとれば,確率とみなしうる。
- すなわちソフトマックス関数とは,実数値をとるニューラルネットワークの出力を確率に変換し,その最大値を強調するように作用することが分かる。
- ソフトマックス関数をニューラルネットワークモデルの最終層の出力とした場合,学習に用いられる教師信号もワンホット表現されていれば,ワンホット表現を近似する目的でソフトマックス関数は用いられていると解釈することもできる。
- ソフトマックス関数は,数ある候補項目の中から,一つを選ぶという意思決定に用いられる。
- ソフトマックス関数は,数ある候補項目の中から,唯一つの項目に着目するという意味で,注意機構に用いられる。
- ソフトマックス関数において,考慮すべき項目が x と y と2 つしかない場合,
\(p(x) = \frac{\exp(x)}{\exp(x)+\exp(y)}=\frac{1}{1+\exp(-(x-y))}=\frac{1}{1+\exp(-Z)}\)
ここで,$z=(x-y)$,と書くことができる。 上式は,ロジスティック回帰などでも用いられる,ロジスティックシグモイド関数である。 2 値分類問題における真偽値,コーホート分析における生存確率などとも考えることができる。 - ソフトマックス関数の分母に現れる $\sum_{j}\exp(x_{j})$ は,物理学 (統計力学,熱力学) における分配関数 partition function と形式的には同じ形をしている。
- このことは,ニューラルネットワークの出力層の素子全体を,熱力学的系と同一視して考えることができることを意味する。熱力学的エネルギーであり,熱力学的エントロピーと情報論敵エントロピーが同じ式をしていることが,ソフトマックス関数の定義から導出できる。
まとめると,ワンホットベクトルを埋め込みベクトルに変換することは,記号表現を高次元実空間へ射影することであり,反対に,埋め込み表現を,ソフトマックス関数を用いて記号表現へ変換することで,記号 (あるいは規則,言語) と分散表現,脳内の神経活動へと変換する橋渡しができることとなる。
言語と機能的脳画像研究を結びつけるために,単語の分散表現を機械学習的手法で表現
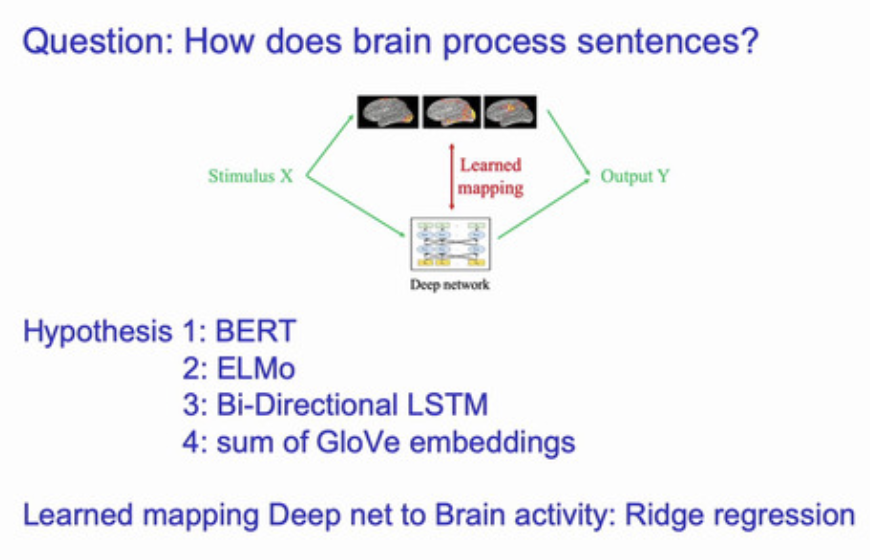
下図 左のように,「セロリ」から右の脳画像を予測するために,中間表現として,兆 単位の言語コーパス (言語研究では訓練や検証に用いる言語データをコーパスと呼ぶ) から得られた 意味特徴 を用いる

他の単語 (下図左) eat, taset, fill などの単語から セロリ を予測する回帰モデルを使って予測

BERT: 埋め込みモデルによる構文解析
BERT の構文解析能力を下図示した。 各単語の共通空間に射影し,単語間の距離を計算することにより構文解析木と同等の表現を得ることができることが報告さ れている [@2019HewittManning_structural]。
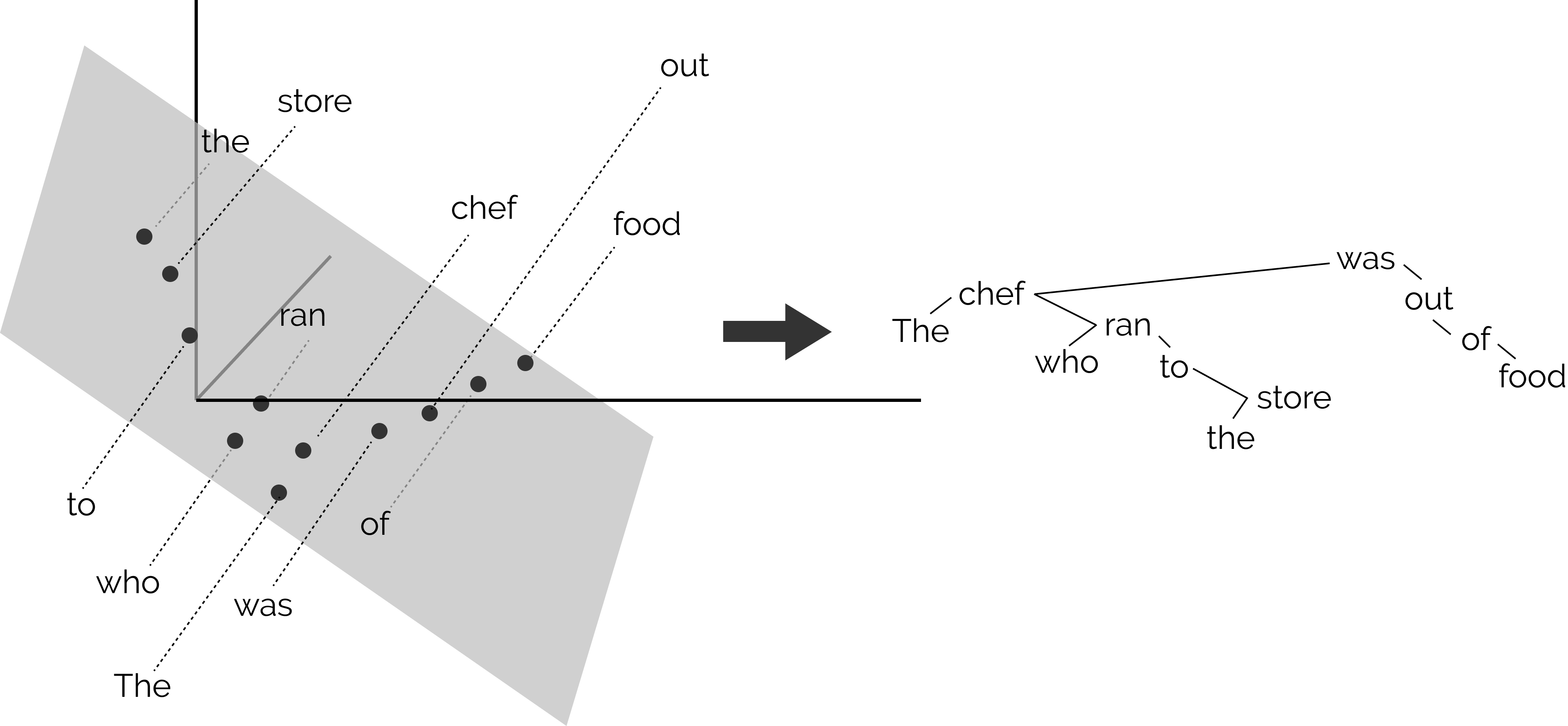
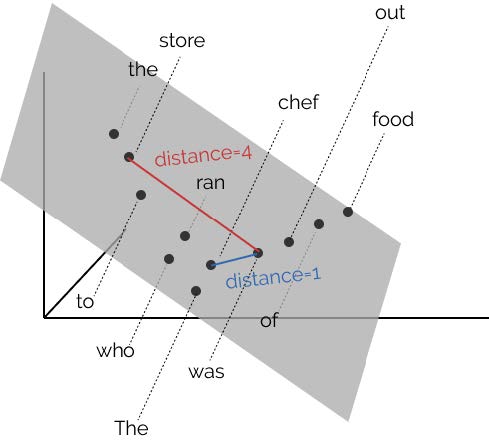
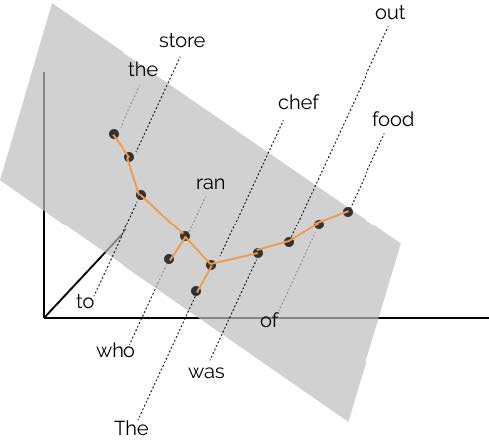
word2vec において単語間の距離は内積で定義されていた。 このことから,文章を構成する単語で張られる線形内積空間内の距離が構文解析木を与えると見なすことは不自然ではない。
そこで構文解析木を再現するような射影変換を見つけることができれば BERT を用いて構文解析が可能となる。 例えば上図における chef と store と was の距離を解析木を反映するような空間を見つけ出すことに相当する。 2 つの単語 $w_i$, $w_j$ とし単語間の距離を $d\left(w_i,w_j\right)$ とする。 適当な変換を施した後の座標を $h_i$, $h_j$ とすれば,求める変換 $B$ は次式のような変換を行なうことに相当する:
\[\min_{B}\sum_l\frac{1}{\left|s_\ell\right|^2}\sum_{i,j}\left(d\left(w_i,w_j\right)-\left\|B\left(h_i-h_j\right)\right\|^2\right)\]ここで $\ell$ は文 s の訓練文のインデックスであり,各文の長さで規格化することを意味している。
単語埋め込みモデル word2vec


skip-gram と CBOW
- Mikolov は word2vec によりニューラルネットワークによる意味実装を示した (Mikolov+2013)。
- Word2vec は実装に 2 種類ある。それぞれ CBOW と skip-gram と命名されている。
- “king” - “man” + “woman” = “queen” のアナロジーを解くことができると喧伝された。
- 下図左は意味的なアナロジーがベクトルの向きとして表現されていることに注目。
ベクトルは方向と大きさを持っている矢印で表現される。 このとき,矢印の原点を移動することを考える。 たとえば “MAN” から “WOMAN” へ向かう矢印を平行移動して “KING” まで持ってくると,その矢印は “QUEEN” を重なることが予想できる。 これがアナロジー問題の解放の直感的説明である。
- word2vec の実装には 2 種類ある。どちらを使っても同じような結果を得ることが可能である。
- CBOW: Continous Bog of Words 連続単語袋
- skip-gram: スキップグラム
両者は反対の関係になrる。下図を参照。

From Mikolov+2013, Fig. 1
CBOW も skip-gram も 3 層にニューラルネットワークです。その中間層に現れた表現を ベクトル埋め込みモデル あるいは 単語埋め込みモデル と言う。
- CBOW モデルは周辺の単語の単語袋詰め表現から中央の単語を予測
- skip-gram は中心の単語から周辺の単語袋詰表現を予測
たとえば,次の文章を考える:
["彼", "は", "意味論", "を", "論じ", "た"]
表記を簡潔にするため各単語に ID を割り振ることとする。 すると上文は,単語 ID を用いて以下のように表現される:
{"彼":0, "は":1, "意味論":2, "を":3, "論じ":4, "た":5}
[0, 1, 2, 3, 4, 5]
ウィンドウ幅がプラスマイナス 2 である CBOW モデルでは 3 層の多層パーセプトロンの入出力関係は,入力が 4 次元 ベクトル,出力も 4 次元ベクトルとなる。 文の境界を無視すれば,以下のような入出力関係とみなせます。
負事例サンプリング
Word2vec を使って大規模コーパスを学習させる際に,学習させるデータ以外に全く関係のない組み合わせをペナルティーとして与えることで精度が向上する (Mikolov+2013)。
罰則項に,乗する重みをどの程度にするかは,経験による。
ベクトル空間
- ピラミッド・パームツリー・テスト: 認知症検査 (意味連合検査,佐藤2022)
- ターゲットと最も関連のあると考えられる選択肢を一つ選べ。
- ターゲット: オートバイ,選択肢: 麦わら帽子,帽子,ヘルメット,兜
- ターゲット: かもめ,選択肢: 水田,池,滝,海
- ターゲット: 柿,選択肢: 五重塔,教会,病院,駅



人工ニューラルネットワークと神経細胞の機能的類似
人工ニューラルネットワークと脳の反応特性の類似性は,これらのモデルが脳の計算の重要な側面を捉えている可能性を示す
- 両者 (ニューラルネットワークと神経細胞) 共に階層的,多層的
- 画像の画素からの情報は通常,十数層の「ニューロン」(ノード) を通して処理される
- 類似した組織に加えて,その活性化も類似
- 初期ノードは Gabor のような受容野を持つ (Güçlü&van_Gerven2015),V1 に見られるエッジ検出器と類似
- これらのネットワークの初期層/中間層/後期層における活性化は,それぞれ V1/V4/IT 反応 (個々のニューロンと fMRI 反応の両方) を予測 (Yamins&DiCarlo2016, Yamins+2014, Khaligh-Razavi&Kriegeskorte2014, Güçlü&van_Gerven2015)。
- 深層ニューラルネットワークは,物体認識において視点に対して同様に不変 (Kheradpisheh+2016a,b)
- 画像間で同様に反応し (Khaligh-Razavi&Kriegeskorte2014),同様のタイプのエラーを犯す (Kheradpisheh+2016a,b)
-
後頭頂ニューロンと,視覚的場面で物体の位置を特定するよう訓練された神経回路網との類似性が示された (Zipser&Andersen 1988)。
-
情景認識について訓練されたネットワークは,後頭葉の場所領域における反応を正確に予測 (Bonner&2018)。
- 音声認識と音楽ジャンル予測について訓練されたネットワークは,聴覚皮質と同様の活動を示す (Kell+2018)。
- サルの動きを再現するように訓練されたリカレントニューラルネットワークには,一次運動皮質のニューロンと選択性が非常によく似た活動をするユニットが含まれる (Sussillo+2015)。
- ナビゲーション課題を訓練したリカレントネットワークの素子は,嗅内皮質や海馬のグリッド細胞や場所細胞と似た活性を持つ (Kanitscheider&Fiete2017, Cueva &Wei2018, Banino+2018)。
3. 符号化器・復号化器モデル
3.1 言語モデル
言語モデル (LM: Language Model) とは,単語系列 $w_t, t\in[0,t]$ が与えられたとき,次単語 $w_{t+1}$ の確率を予測することを指す。
\[\begin{aligned} L &= \max -\log p(x) & \text{ 負の対数尤度 negative log likelihood}\\ &= \max -\log p(x_{t+1}|x_{t}) & \text{ uni-gram}\\ &= \max -\log p(x_{t+1}|x_{t},x_{t-1}) & \text{ bi-gram}\\ &= \max -\log p(x_{t+1}|x_{t},x_{t-1},x_{t-2}) & \text{ tri-gram}\\ &= \max -\log p(x_{t+1}|x_{t},x_{t-1},x_{t-2}, x_{t-3}) & \text{ quad-gram}\\ &= \max -\log p(x_{t+1}|x_{t},x_{t-1},x_{t-2}, x_{t-3}) & \text{ quint-gram}\\ \end{aligned}\]t 番目の位置に現れる単語を $w_t$ と表記し,その確率を $p(w_t)$ とする。 このとき,次式を言語モデル LM と呼ぶ。
最も単純なモデルでは,直前に現れた単語のみによって定まるモデル $p(w_t|w_{t-1})$ である 。 この場合には,総単語数を $|V|$ とすれば,言語モデルが保持しなければならない記憶容量は $|V|^2$ で与えられる (バイグラム bi-gram 言語モデル)。 直前の 2 単語から定まるモデルでは $p(w_{t}|w_{t-1},w_{t-2})$ であるが,この場合の記憶容量は $|V|^3$ となる (トリグラム tri-gram 言語モデル)。 Transformer で採用された語彙数は $|V|=32,000$ である。 従って,$|V|^n$ の際に必要となる記憶容量は,膨大である。
このことは,統計的言語モデルにとって大きな制約となっていた。 言語モデルの記憶容量問題を解決する手法として,リカレントニューラルネットワークに基づく言語モデル (neural network language models: NLM) が用いられてきた (Mikolov+2010)。 リカレントニューラルネットワークを言語モデルとして用いれば,上記記憶容量の問題は発生しない。
だが,NLM では,長距離依存 long term dependency を解消する問題が残されていた。 このため,エルマン型の単純再帰型リカレントニューラルネットワークではなく,LSTM や GRU といった,長期記憶を調整する機構を持ったリカレントニューラルネットワークを用いることが試みられてきた。
以下に示す,翻訳モデルでは,加えて注意機構を実装することにより,長距離依存解消に対応することが試みられてきた。
3.2 翻訳モデル (Seq2seq model)

eos は文末を表す。
中央の eos の前がソース言語であり,中央の eos の後はターゲット言語の言語モデルである SRN の中間層への入力
として用いる。


3.3 注意機構
注意すべきは,ソース言語の文終了時の中間層状態のみをターゲット言語の最初の中間層の入力に用いることであり,それ以外の時刻ではソース言語とターゲット言語は関係がない。 逆に言えば最終時刻の中間層状態がソース文の情報全てを含んでいるとみなしうる。 この点を改善することを目指すことが 2014 年以降盛んに行われてきた。 顕著な例が後述する 双方向 RNN,LSTM 採用したり,注意 機構を導入することであった。
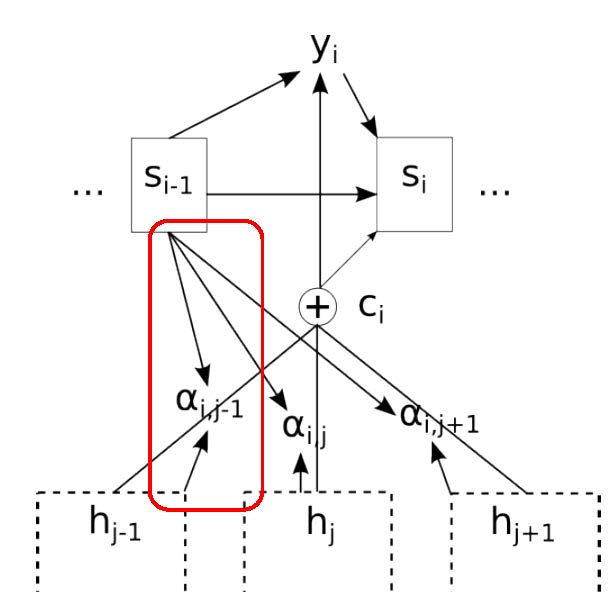

3.4 注意機構を用いて系列データを処理する Transformer



上図で,matmul は行列の積,scale は,平均 0 分散 1 への標準化,mask は 0 と 1 とで,データを制限すること,softmax はソフトマックス関数である。
トランスフォーマーの注意とは,このソフトマックス関数である。