DaSiC 7 (2023) Linguistics and Data Science in Collaboration 発表資料
Shin Aasakawa, all rights reserved.
https://opensource.org/license/mit/
実演 鏡を覗いてみると
146 (ニーチェ,木場深定訳,善悪の彼岸,120ページ,岩波書店)
左から,正四面体,正六面体,正八面体,正十二面体,正二十面体
Table of contents: part 3 第三部目次 (16:25-17:40)
- ちはやふる Transformer を用いた符号化器・復号化器モデルによる百人一首
- ヨコ型,タテ型の言い誤りのシミュレーション Horizontal and vertical errors in speech errors
実習ファイル
0. 双対性 duality
機械学習,あるいは,最適化理論において,双対性 duality または双対性原理 duality principle とは,最適化問題を主問題 primal problem と双対問題 dual problem の 2 つの観点から見ることができることを指す。 主問題 primal problem が最小化問題であれば,双対問題 dual problem は最大化問題である (逆も同様)。 主問題 (最小化問題) に対するどのような実行可能解も,双対問題 (最大化問題) に対するどのような実行可能解も,少なくとも同じ大きさである。 したがって,原始問題の解は双対問題の解の上界であり,双対問題の解は主問題の解の下界である。この事実は弱双対性 weak duality と呼ばれる。
Lagrange 双対問題は,非負の Lagrange 乗数を用いて目的関数に制約を加えることによって最小化問題の Lagrangian を形成し,元の目的関数を最小化する主変数の値を解くことによって得られる。 この解法は,Lagrange 乗数の関数として主変数を与え,これを双対変数と呼ぶ。 従って,新しい問題は,双対変数に関する制約 (少なくとも非負制約を含む) の下で,双対変数に関して目的関数を最大化することである。 von Neumann によれば,双対問題と呼ばれる別の視点を用いることで,主問題または双対問題のどちらを解いても最適解が得られるという理論を概念化できる。
1. ちはやふる Transformer を用いた符号化器・復号化器モデルによる百人一首
- データ: http://www.diana.dti.ne.jp/~fujikura/List/List.html
- かるた取り遊びを意識して,すべての歌で,ひらがな表記されたデータを用いた。
- 課題: 上句をエンコーダに入力し,デコーダに下句を予測させる。
- 構成単位として Transformer を用いた。
- 訓練時間短縮のため,1 層のみ。素子数は 32,注意ヘッド数 4,最大系列長 22
1.1 Transformer, Attention is all you need
単語の多義性解消のために,あるいは単語のベクトル表現を超えて,より大きな意味単位である,句,節,文のベクトル表現を得る努力がなされてきた。 適切な普遍文表現ベクトルを得ることができれば,翻訳を含む多くの下流課題にとって有効だと考えられる。
そこで,注意機構を積極的に取り込んだゲームチェンジャーが Transformer である。



上図で,matmul は行列の積,scale は,平均 0 分散 1 への標準化,mask は 0 と 1 とで,データを制限すること,softmax はソフトマックス関数である。
- 注意を用いて,RNN を置き換える Devlin+2017,Attention Is All You Need
- Transformer の注意とは,このソフトマックス関数である。
- 専門用語としては,多頭=自己注意 Multi-Head Self-Attention (以下 MHSA と表記)と呼ぶ。
- 自己 がつく注意である理由は,トップダウン信号がないためであろう。
- 上図,クエリ,キー,バリュー ,意味としては,問い合わせ,キー(鍵),値,であるが,とりわけ,Q と K との間に明確な相違はない。
- ある問い合わせ Q に対して,キー K を与えて,その答え A となる値を得ることに相当する。
- この操作を入力情報から作り出して答えを出力する仕組みに,ワンホット表現を使う。
- 図中央の Scaled Dot-Product Attention と書かれた右脇に小さく h と書かれている。この h とは ヘッド の意味。
- 図中央を 1 つの単位として,次に来る情報と連結させる。図右。
- リカレントニューラルネットワークでは,中間層の状態が次の時刻の処理に継続して用いられていた。
- ところが 多頭=自己注意 MHSA では一つ前の入力情報を,現在の時刻の情報に対するクエリとキーのように扱って情報を処理する。
- 図右の下から入力される情報は,input と output と書かれている。 さらに output の下には (Shifted right) と書かれています。 すなわち,時系列情報を一時刻分だけ右にずらし(シフト)させて逐次情報を処理することを意味している。
- 図右の下から入力される情報は,embedding つまり埋め込み表現 と 位置符号化 position embedding が足し合わされたもの。 埋め込み表現とは先週 word2vec で触れたベクトルで表現された,単語(あるいはそれぞれの項目)の 意味表現 に対応。
1.2 Transformer における位置符号化器 (PE: position encoders)
\[\text{PE}_{(\text{pos},2i)} = \sin\left(\frac{\text{pos}}{10000^{\frac{2i}{d_{\mathop{model}}}}}\right)\] \[\mathop{PE}_{(\mathop{pos},2i+1)} = \cos\left(\frac{\mathop{pos}}{10000^{\frac{2i}{d_{\mathop{model}}}}}\right)\]1.3 事前訓練
マスク化言語モデル

次文予測課題
言語モデルの欠点を補完する目的,次の文を予測
[SEP] トークンで区切られた 2 文入力
- 入力: the man went to the store [SEP] he bought a gallon of milk.
- ラベル: IsNext
- 入力: the man went to the store [SEP] penguins are flightless birds.
- ラベル: NotNext
ファインチューニング GLUE 課題 (General Language Understanding Evaluation)
- CoLA: 入力文が英語として正しいか否かを判定
- SST-2: スタンフォード大による映画レビューの極性判断
- MRPC: マイクロソフトの言い換えコーパス。2 文 が等しいか否かを判定
- STS-B: ニュースの見出し文の類似度を5段階で評定
- QQP: 2 つの質問文の意味が等価かを判定
- MNLI: 2 入力文が意味的に含意,矛盾,中立を判定
- QNLI: 2 入力文が意味的に含意,矛盾,中立を判定
- RTE: MNLI に似た2つの入力文の含意を判定
- WNI: ウィノグラッド会話チャレンジ
1.4 Transformer (SBERT) の文ベクトル
先に紹介した word2vec は,単語ベクトルを得る手法であるが,Transformer は文ベクトルを扱う。 そこで,文単位での類似性を検討した。 下の画像に対して,5 つの脚注がある。
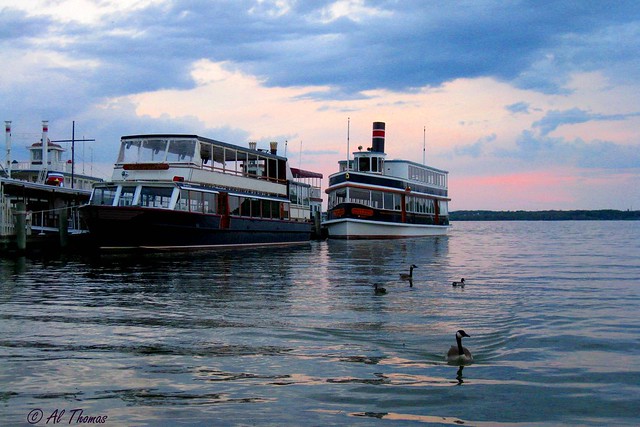
- 夕暮れのハーバーに汽船と複数の鳥が浮かんでいる
- 水面に浮かぶ4羽の水鳥と、その向こうに停泊している2隻の船
- 船着き場に2艘の船がとまっている
- 朝焼けの中待機場所にある旅客船とマガモ
- 停められた船の近くで水鳥が泳いでいる
MS COCO データセットより: http://farm5.staticflickr.com/4055/4704393899_a041476b4a_z.jpg
{kind=link}
上図は,MS COCO 画像データと画像に対応する脚注からなるデータセットからの一例である。 日本語文は,千葉工業大学 STAIRLABO が公開しているデータである。 人間が見れば,写真と文章とは結びいていることが分かる。 加えて,5 つの脚注も相互に似ていることが分かる。 MS COCO データセットでは,一枚の写真に 5 つの脚注が紐付けられている。
コンピュータにこれらの文章が似ていることを判断させようとすると,最近まで難しい仕事であった。 本章で紹介する,文の意味ベクトルを用いると,これらの文章が相互に似ていると判断させることが可能である。 下図は tSNE を用いて,日本語の文章の類似度を sentence BERT を用いて表現し,文章の類似度に従って地図を描いたものである。 図では,同じ写真に紐付いている文章は同じ色で表現している。

1.3 性能評価 intstructGPT (a.k.a chatGPT)
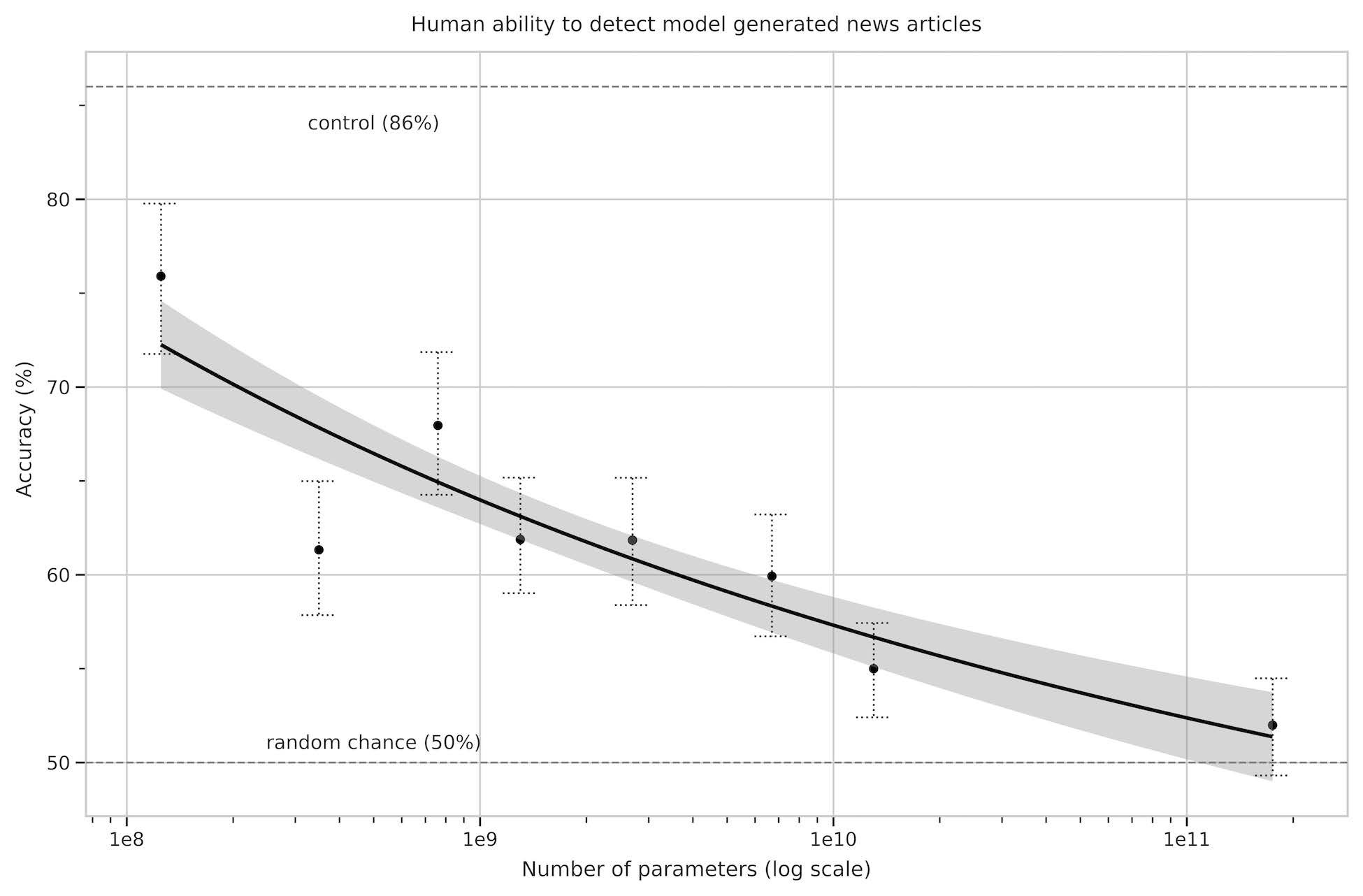
1.4 結果
- エポック:1 損失:2.97051 正解率: 1.000%
- エポック:2 損失:1.22301 正解率: 54.000%
- エポック:3 損失:0.46482 正解率: 76.000%
- エポック:4 損失:0.18355 正解率: 97.000%
- エポック:5 損失:0.07385 正解率: 100.000%
- エポック:6 損失:0.03077 正解率: 100.000%
エポック 4 終了時のエラーは以下のとおり:


2. ヨコ型,タテ型の言い誤りのシミュレーション
2.1 モデル
- 84300 文を訓練。Transformer を用いて,文の復唱を学習。
- 語彙数 32000. 層数 2, 素子数 384, 注意ヘッド数 4, (BERT えは,語彙数 32000,層数 12,素子数 768, 注意ヘッド数 12)
- 事前訓練データとして,長岡技術大学で公開されている やさしい日本語 データを使用
- タテ型の言い誤り,ヨコ型の言い誤りのそれぞれで微調整
2.2 結果
- ヨコ型の言い間違えの再現率,(すなわちエンコーダに意図文を入れて,言い間違え文をデコーダに出力する) は 97.778 %
- タテ型の言い間違えの再現率は 90.000 %
一見すると,タテ型の言い間違えの方が再現できていないように見えますが,学習語彙に含まれない語彙が多いという理由かも知れない。 ヨコ型の再現失敗例を以下に示す:
| 出力 言い誤り 文 | 入力 意図 文 |
|---|---|
| 足の筋肉は収縮すると、もう足の、非常にいろんな点でね、足の[UNK]環を良くしますし | 入力文:足の筋肉は収縮すると、もう足の、非常にいろんな点でね、血液の循環を良くしますし |
| 出力文:このアブラムシがいわゆる寄生しますとね、アブラカスの分[UNK]物をね… | 入力文:このアブラムシがいわゆる寄生しますとね、アブラムシの分泌物をね… |
| 出力文:重傷の火傷はね、皮[UNK]が無いために水分が出てしまって、タンパク質が出てしまって、非常に重傷になるわけです | 入力文:重傷の火傷はね、皮膚が無いために水分が出てしまって、タンパク質が出てしまって、非常に危険になるわけです |
以上がヨコ型言い間違え,再現失敗例の全てであった。
一方,タテ型言い間違え再現失敗例は以下のようになった:
| 出力 言い誤り 文 | 入力 意図 文 |
|---|---|
| ロンドン、ボストンていう便はさ… | ロサンゼルス、ボストンていう便はさ… |
| 御前崎、波は2メートル、うなりは不明 | 御前崎、波は2メートル、うねりは不明 |
| 今日[UNK]枚組のタオルを | 今日のプレゼントクイズはこの6枚組のタイルを |
| 大相撲初場所[UNK]日目千秋楽の一番 | 大相撲初場所6日目結びの一番 |
| 水戸三高[UNK]年生、なかなかスケールのおおいランナーです | 水戸三高の3年生、なかなかスケールのおおきいランナーです |
| 広島ノー・[UNK]、[UNK]塁というピンチをつかんだんですが | 広島ノー・アウト2、3塁というチャンスをつかんだんですが |
| 乾[UNK]して砂が浮いてきた | 乾燥して石が浮いてきた |
| さんと長谷川[UNK]点[UNK]点で同意語で | さんと長谷川さんが7点と7点で同同点で |
| [UNK]年から国の政治としてとりいれられた | 48年から国の制度としてとりいれられた |
| [UNK]通くらい募集があったというけれども、応募かね | 70通くらい応募があったというけれども |
| ゲームは第[UNK]入ってジェッツの攻撃 | ゲームは第2クォーターに入ってジェッツの攻撃 |
| [UNK]回ワンナウト、これでゲームあったかにみえましたが | 9回ワンナウト、これで勝負あったかにみえましたが |
| [UNK]、[UNK]塁、一人はシングルヒット、もう一人はデッドボールを選んで塁に出ています | ランナー1、2塁、一人はシングルヒット、もう一人はフォアボールを選んで塁に出ています |
| [UNK]年までに、あの水準まで、あの、とどけようと | 59年までに、あの水準まで、あの、到達しようと |
| 歌舞[UNK]なんかでね、主人公がやせていたらこれはえになんない | 歌舞伎なんかでね、主人公がやせていたらこれは芝居になんない |
| [UNK]日目まで優勝 | 5日目まで全勝 |
| [UNK]子をコの字形に並べて | 机をコの字形に並べて |
| この方は明治[UNK]年代の御出身で | この方は明治40年代のお生まれで |
| [UNK]角度で | 45メートルの高さで |
| [UNK]年の民社党の分裂とかですね | 35年の民社党の独立とかですね |
文中の [UNK] は,そもそも学習語彙中に存在しないので,学習しようがない。 [UNK] トークンの問題を考慮すれば,タテ型の言い誤りも,再現できているように思われる。
3. 考察
ここまでをまとめると以下のようになる:
- 大規模データに基づくモデルに対して,課題に合わせて,目的関数を事前訓練を行ったモデルに対して,関心のある現象,患者,条件に合わせた微調整を加えた。
- すなわち,目的関数の制約項を変化させることで,行動データ再現させることを試みた。
- Dell モデルにおいては,温度パラメータ,および,S, p パラメータを目的関数として微調整を行った。
- 復唱モデルにおいては,注意機構とリカレント接続とに制約を設けて,微調整を行い,健常者と失語症患者との違いを記述した。
- これらのシミュレーションは,制約項付きの最適化とみなすことが可能。
- モデル,データ,パラメータの三項を考えることで,モデルとデータからパラメータを眺め,モデルとパラメータからデータを眺め,データとパラメータからモデルを眺めることになっているだろう。
3.1 制約項からみた定式化
機械学習における目的関数 (損失関数) は次式で与えられる:
\[\tag{一般形} \text{目的関数} = \text{誤差} + \lambda\left(\text{正則化項}\right)\]ここで,$\lambda$ は Lagrange 乗数である。
word2vec においては,
\[\tag{word2vec} \text{目的関数} = \text{標的単語との誤差} + \lambda\left(\text{負事例 ただし ランダムにサンプリング}\right)\]で与えられていた。 Dell モデルのパラメータ推定においては,次式となる:
\[\tag{Dell model} \text{目的関数} = \text{単語カテゴリ確率との誤差} + \lambda_{1}\left(\text{s,p パラメータへの制約}\right) + \lambda_{2}\left(\text{w,d パラメータへの制約}\right) + \lambda_{3}\left(\text{温度パラメータ $\beta$ への制約}\right)\]一方,エンコーダ・デコーダモデルにより言い間違えのシミュレーションでは,次式で与えられる:
\[\tag{speech errors} \text{目的関数} = \text{正しい単語と言い間違え単語との誤差} + \lambda_{1}\left(\text{注意機構への制約}\right) + \lambda_{2}\left(\text{フィードバック機構への制約}\right)\]同様にして,タテ型,ヨコ型の言い間違え Transformer モデルでは,次式を用いた:
\[\tag{speech errors Transformer 1} \text{目的関数} = \text{正しい文と言い間違え文との誤差} + \lambda_{1}\left(\text{ヨコ型言い間違えに対する制約}\right)\] \[\tag{speech errors Transformer 2} \text{目的関数} = \text{正しい文と言い間違え文との誤差} + \lambda_{1}\left(\text{タテ型言い間違えに対する制約}\right)\]式 (speech errors Transformer 1) と 式 (speech errors Transformer 2) との関連は,現在のところ不明である。 しかし,本モデルでは,文法知識の制約,例えば Dell+2008 のごとき 構文的交通巡査 (traffic cop) のような機構を仮定しなかった。 むしろ Transformer による本モデルでは,文法的,統語的な規則を明示的に記述せず,訓練コーパスの学習を通じて,ニューラルネットワークのアーキテクチャと結合係数へと反映された点に留意スべきである。
4. 議論 ありえない有能さ Unreasonable effectiveness
Lagrange 乗数を,変分問題として定式化し,制約項に対する意味付けを考えるアプローチは,物理学で始められた。 制約付き最適化は,画像復元においては 標準正則化理論 (Poggio+1985) で定式化された。 機械学習においては,汎化性能向上のための制約と考えられてきた。 近年では,目的関数とと制約項と与え方を検討することで,GAN や stable diffusion 等の生成 AI でも用いられている。
変分 Bayes の考え方でも同様であり,目的関数を Lagrange 方程式とみなせば,目的関数 (主問題) の最小化問題を,制約項付き双対問題の最大化ととらえうる。 このようにして,他分野で提唱された概念を,援用することで現象を見通しよく説明できる。 補足資料 変分問題と標準正則化 も参照のこと。
- 1960: 自然科学における数学のありえない有能さ, Wigner1960
- 1980: 数学のあり得ない有能さ, Hamming
- 2009: データのありえない有能さ, Halevy+2009
- 2015: リカレントニューラルネットワークのあり得ない有能さ, Karpathy2015
- 2016: 工学のあり得ない有能さ (これだけは論文のタイトルではない), Yamis+2016
- 2018: 忘却ゲートのあり得ない有能さ, Westhuizen&Lasenby2018
- 2020: 人工知能のあり得ない有能さ, Sejnowski2020
- 2021: ニューラルネットワーク埋め込みのあり得ない有能さ, Gao2021
主張 Takeaways (再) まとめ
- 大規模言語モデル (LLM),一般画像錦 (ImageNet) で事前訓練されたモデルに対して,転移学習 transfer learning を行うことで,関心領域の課題を解くモデルを作成
- 関心課題に特化したモデルに対して,任意の条件とデータとを用いて,微調整 fine-tuning を行うことで,条件間の差異や生成機序を解明。
- モデル,データ,パラメータ の三項は,言語学的規範,行動・臨床データ,機械学習モデルの三項と連結。微調整に用いる条件は,制約条件付き最適化 constrained optimization とみなしうる。このことは,データサイエンスにおける,モデルとパラメータの関する双対性原理 duality principle として定式化
キーワード keywords
符号化・復号化モデル,転移学習,微調整,トランスフォーマー,注意,ソフトマックス,ワンホットベクトル, 埋め込み表現,ラグランジェ双対性
Encoder-decoder models, Transfer learning, Fine-tuning, Transformer, Attention, Softmax, onehot vector, Embeddings, Lagrange duality,